31 Mixture of Experts (MoE)
Es una arquitectura que combina varios modelos especializados (“expertos”) para resolver una tarea. En vez de entrenar una inmensa red general que responda todo tipo de preguntas, se entrenan múltiples modelos más pequeños, cada uno especializándose en áreas específicas como programación, matemáticas o idiomas.
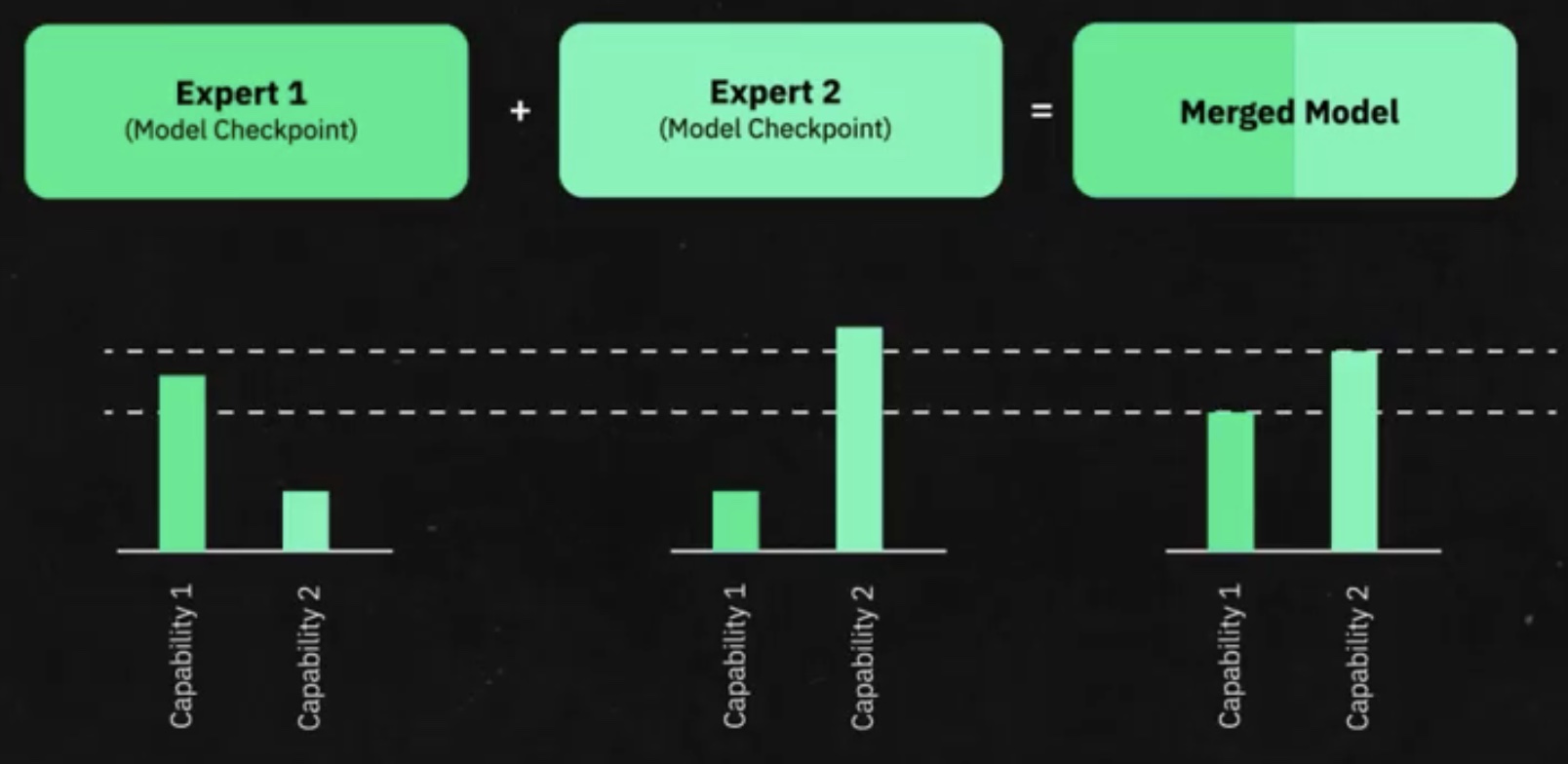
Cada uno de estos expertos actúa de forma independiente durante el entrenamiento inicial y posteriormente se combinan. El resultado es una arquitectura eficiente que utiliza solo una pequeña porción de parámetros durante la inferencia.
Para implementar esta arquitectura utilizamos nuestro corpus con clasificaciones, las cuales entrenan mini modelos que responden a tareas específicas. Luego, se realizan fines tuning a las respuestas de estos modelos, y, finalmente, se deben unir.
31.1 ¿Como hace el LLM para activar los expertos?
Utilizanso la denominada gate network. Esta “red gate” funciona como un guía intuitivo, reconocido por identificar rápidamente qué expertos deben activarse según la consulta específica realizada por el usuario.
Es una mini red neuronal que fue entrenada para conocer cada categoría del LLM, y que sabe “dónde buscar”.
Esta get network se compone de dos caraterísticas priniciaples:
Sparsity (esparcidad): técnica que asegura que la gate network dirija únicamente hacia expertos relevantes, evitando activar innecesariamente áreas de la red no útiles.
Load balancing: en entrenamiento e inferencia asegura que los expertos se activen adecuadamente en función de la tarea requerida.