30 Escalado y modelos multimodales
Las leyes de escalado y los modelos multimodales son esenciales en el ámbito actual de la inteligencia artificial. Aumentar los parámetros, la cantidad de datos y la capacidad computacional mejora el desempeño, aunque con retornos decrecientes tras cierto punto. A su vez, los modelos multimodales combinan diferentes tipos de información, permitiendo aplicaciones avanzadas en diversos contextos.
30.1 Leyes de escalado
Las leyes de escalado revelan cómo mejora previsiblemente el rendimiento de un modelo al incrementar ciertos recursos clave. Estos recursos son:
Parámetros del modelo.
Datos disponibles para entrenamiento.
Capacidad computacional.
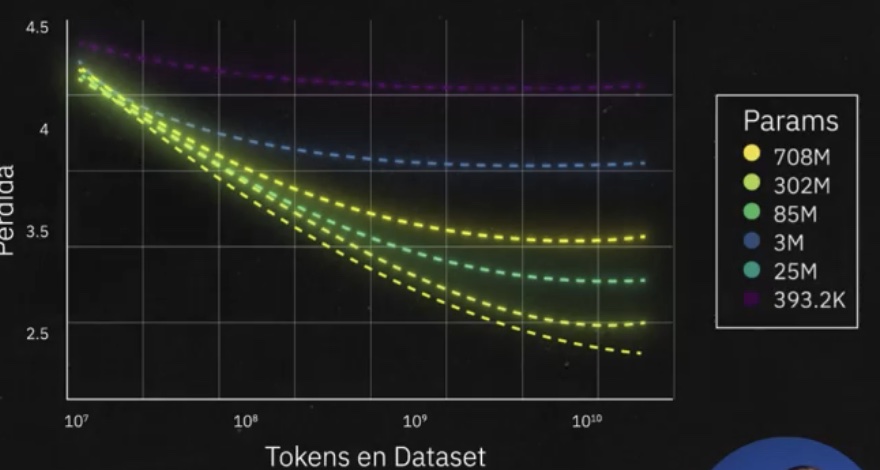
En esta imagen podemos observar que, para GPT3, la pérdida disminuyó al momento de aumentar los parámetros del modelo y aumentar la cantidad de datos de entrenamiento.
La relación entre el rendimiento y los recursos sigue una ley matemática conocida como ley de potencia, mostrando cómo al aumentar recursos específicos, los errores o pérdidas disminuyen con predictibilidad.
No obstante, llega un punto donde este incremento adicional tiene un efecto menor, lo que se conoce como retornos decreciente, por eso es importante mantener el equilibrio, así no sacrificamos potencial ni tenemos grandes pérdidas en los modelos.
30.2 Modelos multimodales
Los modelos multimodales en inteligencia artificial son sistemas capaces de procesar y combinar información proveniente de diferentes tipos de datos o “modalidades”, como texto, imágenes, audio y video.
A diferencia de los modelos tradicionales que solo trabajan con un tipo de dato (por ejemplo, solo texto o solo imágenes), los modelos multimodales pueden entender y relacionar información de varias fuentes al mismo tiempo.
Esto les permite tener una comprensión más completa y contextual del mundo, facilitando tareas como describir imágenes con texto, responder preguntas sobre videos, o analizar conversaciones que incluyen voz y texto.
Ejemplos actuales de modelos multimodales incluyen GPT-4 (que puede analizar texto e imágenes) y CLIP (que relaciona imágenes y descripciones textuales).