5 Malla de validación
Una malla de validación permite revisar de manera automática la consistencia de la información proveniente de cada encuesta y los rangos de las respuestas, identificando de manera automática cuando un valor o respuesta específica no corresponda a un rango, previamente determinado, o cuando una respuesta sea inconsistente en relación a respuestas anteriores, según los saltos específicos de cada instrumento.
Veremos como programar los siguientes tipos de errores:
errores de valores perdidos, asociados a preguntas de respuesta obligatoria que se encuentren sin respuestas (missing);
errores de programación, como saltos o filtros mal aplicados o preguntas de respuesta múltiples que carezcan de respuesta en al menos una opción;
errores de consistencia, como datos fuera de rangos o extremos (datos que se escapan de los rangos, Ej: Edad.), y detectar inconsistencias lógicas en las respuestas de los participantes.
Data a utilizar
Para el ejercicio, se utilizará la base de datos de la Encuesta Nacional de Uso del Tiempo (ENUT) 2015.
Se utilizarán dos versiones de dicha BBDD: una corregida tal como se puede descargar desde la pagina web del Instituto Nacional de Estadísticas y una alterada, en la que se introdujeron errores a propósito para ilustrar el funcionamiento de la malla de validación.
Comenzaremos trabajando con la BBDD original
library(haven)
df <- read_sav("BBDD/BASE_USUARIO_corregida.sav")Para descargar los datos hacer click en:
5.1 Errores de valores perdidos
En primer lugar, se deberá verificar todas las variables que debieron a ser respondidas por todos los casos encuestados, no estando sujetas a saltos ni filtros de ningún tipo. Como se trata de preguntas “obligatorias”, por las que todos debieron haber pasado, querremos chequear que efectivamente haya sido así. Para eso, verificaremos que no hayan valores perdidas en dichas columnas.
Para efectos de estandarizar, se utiliza la expresión “ERRORMISSING_[variable]”.
Extra: creacion de un Id , puesto que esta BBDD no lo poseía.
# creacion de Id
df <- df %>%
mutate(Id = paste0(id_vivienda, id_hogar, n_linea_h, id_persona, n_linea_p))5.1.1 a) selección de Id y variables de interés
Para este paso solo debemos cambiar la BBDD y la selección de variables obligatorias para cada caso. Además del identificador de la persona o el folio de la encuesta, el cual siempre debe seleccionarse primero, antes de las variables.
Es decir, se debe utilizar de la siguiente manera:
data_perdidos <- select(BBDD, c(Id, varX:varY))
# Seleccion de variables de interes
# Para este paso debemos asegurarnos que la variable Id quede al inicio de la seleccion
data_perdidos <- select(df, #BBDD
c(Id, 98:101)) # Id, variables.5.1.2 b) casos perdidos por fila y columnas
El siguiente loop nos entrega de manera automática dos objetos:
data_perdidos= en él obtendremos un reporte que nos indicará las variables y el número de Id de la persona encuestada. De esta manera podremos identificar aquellos casos específicos donde se halle un caso perdido.reporte_errormissing= este objeto nos mostrará un conteo de errores totales por variable
# Debemos asegurarnos que el loop comience con la columna 2, debido a que la 1 es el Id: i in 2:ncol.
# Este loop se encuentra estandarizado. Si seguimos el paso anterior, no deberíamos tener
# problemas con copiar y pegar el código.
# OJO: en caso de cambiar el nombre de "data_perdidos" en el paso anterior,
# debemos asegurarnos de actualizar el loop sobrescribiendo con ese nuevo
# nombre. Por ello, es mejor mantener el nombre original.
for (i in 2:ncol(data_perdidos)) {
data_perdidos[,i] <- ifelse(is.na(data_perdidos[i]), 1, 0)
colnames(data_perdidos)[i]<-paste("ERRORMISSING", names(data_perdidos)[i], sep = "_")
rep <- data_perdidos %>% select(starts_with("ERROR"))
reporte_errormissing <- tibble(variable = rep %>% colnames)
reporte_errormissing <- reporte_errormissing %>% mutate(errores = rep %>% colSums(na.rm = TRUE))
#quitar el comentario siguiente si queremos que el reporte no muestre las variables con errores=0
#reporte_errormissing <- reporte_errormissing[reporte_errormissing$errores > 0,]
rm(rep)
}### Opcional 1 ###
# Si lo necesitamos, también podemos integrar los valores perdidos a la bbdd original
# Para realizar este paso es importante contar con un Id, o alguna otra
# variable en común entre los dos conjuntos de datos
df <- full_join(df, data_perdidos, by = "Id")
### Opcional 2 ###
# Si nos cuesta comprender los errores mediante la codificación 0 y 1, tenemos la opción
# de recodificar estos parámetros a otros más intuitivos
# data_perdidos<-data_perdidos %>%
# mutate_at(c(2:ncol(data_perdidos)), recode, '1'='NA', '0'='Con Dato')5.2 Errores de programación
Por otra parte, nos interesará constatar que los saltos o filtros que contempla el cuestionario se encuentren bien aplicados, de manera que todos los encuestados hayan pasado por la secuencia lógica de preguntas que les correspondía.
A modo de ejemplo, en el cuestionario ENUT, quienes respondieron que en sus hogares sí trabajó personal de servicio doméstico durante la semana anterior a aquella en la que fue aplicada la encuestada, debieron responder posteriormente la pregunta respecto a cuántas personas prestaron esos servicios en dicha vivienda.
En este caso, vamos a denominarlos “ERRORPRO_[n° consecutivo del error]”.
Por tanto, vamos a programar dos errores:
ERRORPROG_1= Si responde que la semana pasada SÍ trabajó personal servicio doméstico y luego no responde cuántas personas prestaron esos servicios; y al revés,ERRORPROG_2= Si responde que la semana pasada NO trabajó personal servicio doméstico y luego responde cuántas personas trabajaron
Lo anterior expresado de manera gráfica sería algo así:
Pregunta filtro —> 1. Sí trabajó personal servicio doméstico; 2. No trabajó personal servicio doméstico. Pregunta llegada –> N° de personas que trabajaron
| P. Filtro | P. Llegada | Tipo de error |
|---|---|---|
| 1 (responde que sí) | 3 (debe responder y lo hace) | Filtro correcto |
| 1 (responde que sí) | NA (debe responder y no lo hace) | Error prog 1 |
| 2 (responde que no) | 4 (no debe responder y lo hace) | Error prog 2 |
| NA (no responde) | 2 (no debe responder y lo hace) | Error prog 2 |
| NA (no responde) | NA (no debe responder y no lo hace) | No aplica criterio |
En esta ocasión, se utilizará la base de datos alterada (con errores)
# cargar bbdd
df <- read_sav("BBDD/BASE_USUARIO_alterada.sav")
# crear id (el mismo que el caso anterior)
df <- df %>%
mutate(Id = paste0(id_vivienda, id_hogar, n_linea_h, id_persona, n_linea_p))5.2.1 a) creación de excel y criterios de salto
Para lograr automatizar el proceso, es necesario generar un excel con las siguientes características

Donde:
Salida: variable de filtro. Si tenemos una pregunta filtro que guía a otras múltiples preguntas, debemos repetir la variable filtro las veces necesarias, tal como se muestra en el ejemplo.Llegada: preguntas que debería contestar si se aplica el filtro.Criterio: valor que debe seleccionar la persona para que se haga efectivo el filtro. Este criterio puede establecerse por valores enteros o rangos:
| Criterio | Secuencia | Rangos |
|---|---|---|
| Si responde 1, 2 o 3 debe responder las preguntas de llegada | 1,2,3 | 1:3 |
| Si responde 1 o 3 debe respondes las preguntas de llegada | 1,3 | No aplica |
En este sentido, el ejemplo se leería de la siguiente manera: si la persona responde “sí” en la pregunta f11_1_1, debe responder también la pregunta f12_1_1. A su vez, si responde “sí” en la pregunta f11_1_1, también debería resonder la pregunta f13_1_2
¡IMPORTANTE: ES NECESARIO QUE LAS COLUMNAS DEL EXCEL SE ENCUENTREN EN FORMATO TEXTO!
5.2.2 b) aplicación del loop
El loop que viene a continuación se encuentra automatizado. Si se han seguido correctamente los pasos anteriores y el excel se encuentra correctamente construido no deberían haber problemas en su ejecución.
En este sentido, lo primero que debemos hacer es cargar nuestro excel con las preguntas listas.
library(readxl)
varsprog <- read_xlsx("BBDD/ERRORPROG_EJ.xlsx")Luego, crearemos vectores específicos con los elementos provenientes de nuestro excel.
# vectores de variables y criterios ---------------------------------------
salida<-c(varsprog$Salida)
llegada<-c(varsprog$Llegada)
criterio.salto<-c(varsprog$Criterio)
criterio.salto<- str_replace(criterio.salto, "\\.", ",")El siguiente paso es generar un nuevo objeto donde se almacenen los resultados del loop y que contenga el Id del encuestado, para poder así identificar el caso a caso.
# la seleccion del Id puede cambiar segun BBDD. En este ejemplo el id se
# llamada "Id".
### OJO: si cambian el nombre de "erroresprog" deberán cambiarlo también dentro del loop ###
erroresprog<-data.frame(df$Id)Finalmente, ejecutamos el loop:
# Creamos una funcion que servira para traducir en una secuencia de numeros imputs
# como "1 3" o "9". Para ambos casos devolver?a "1 2 3" y "9" respectivamente
secuencia<-function(objeto){
n<-length(objeto)
seq(objeto[[1]],objeto[[n]])
}
# LOOP
for (i in 1:length(salida)){
# 1ra parte, traducir en un rango de numeros imputs de caracteres como por ejemplo
# "2,5" en los numeros "2 5". imputs como "1:3", en rangos "1 2 3". Y unidades
# como "4", en el numero al que corresponden
ifelse ((str_detect(criterio.salto[i],",")),
rango<- criterio.salto[i] %>% str_split(",") %>%
unlist() %>% as.numeric(),
rango<-criterio.salto[i] %>% str_split(":") %>%
unlist() %>% as.numeric() %>% secuencia
)
# Identifica la posicion en el data frame, de la variable/columna de salto
coordenada1<-grep(paste("^",salida[i],"$",sep=""), names(df))
# Identifica la posicion en el data frame, de la variable/columna de llegada
coordenada2<-grep(paste("^",llegada[i],"$",sep=""), names(df))
# Chequea si la variable de salto tiene obervaciones que cumplen la condicion
# de salto
s.check<-((as.integer(unlist(df[,coordenada1]))) %in% rango)*1
# Chequea si la variable de llegada tiene obervaciones
ll.check<-(!is.na(df)[,coordenada2])*1
# Se pegan los resultados anteriores, que son agregados al otro data frame
# creado previamente, donde se registraron los resultados para cada individuo
revision<-paste0(s.check,ll.check)
erroresprog<-cbind(revision,erroresprog)
rm(coordenada1, coordenada2, ll.check, s.check, rango, i, revision)
}
# Creamos un vector vacio para almacenar los nombres de las variables
nombres.u<-c()
# Ingresamos los nombres de las columnas del data frame de revision, pegando los
# nombres de las variables y salto llegada que correspondan, mas el criterio de salto
for (i in 1:length(llegada)){
x1<-paste0(salida[i],"-",llegada[i], " (",criterio.salto[i],")")
nombres.u<-append(nombres.u,x1)
}
rm(salida, llegada, criterio.salto, i, x1)
# Reordenar base de datos de revision y añadir etiquetas
erroresprog <- rev(erroresprog)
etiquetas <- append("id", nombres.u)
colnames(erroresprog)<-etiquetas
rm(etiquetas, nombres.u, secuencia)
# Recodificar la nomenclatura de error para una mejor comprension
erroresprog<-erroresprog %>%
dplyr::mutate_at(c(2:ncol(erroresprog)),
dplyr::recode,
'11'='FILTRO_CORRECTO',
'10'='ERRORPROG_1',
'01'='ERRORPROG_2',
'00'='NO APLICA')Una vez tengamos los resultados del loop insertos en nuestro objeto erroresprog, podemos generar tablas de frecuecia que nos indiquen la cantidad de errores en las variables.
Para ello utilizaremos la librería sjmisc y su función frq.
library(sjmisc)
# Para generar reportes solo pedimos de la frecuencia de las variables de interes
# frq(errorprog$variable_x)
frq(erroresprog$`f11_1_1-f12_1_1 (1)`)##
## x <character>
## # total N=34575 valid N=34575 mean=3.97 sd=0.17
##
## Value | N | Raw % | Valid % | Cum. %
## --------------------------------------------------
## ERRORPROG_1 | 8 | 0.02 | 0.02 | 0.02
## ERRORPROG_2 | 11 | 0.03 | 0.03 | 0.05
## FILTRO_CORRECTO | 882 | 2.55 | 2.55 | 2.61
## NO APLICA | 33674 | 97.39 | 97.39 | 100.00
## <NA> | 0 | 0.00 | <NA> | <NA>Como vemos, tenemos 8 casos de Errorporg_1 y 11 con Errorprog_2 (aquellos que fueron alterados de forma manual en la BBDD para efectos del ejemplo).
5.3 Errores de consistencia
Finalmente, verificaremos que no existan inconsistencias lógicas en las respuestas de los encuestados (por ejemplo: tener 21 años o menos y afirmar tener nivel educacional de magister o doctarado completo) o la existencia de valores fuera de rango en variables númericas (por ejemplo, variable de edad con casos menores de 18, si es que solo debían responderla mayores de edad).
En este caso, vamos a denominarlos “ERRORCON_[n° consecutivo del error]”.
A modo de ejemplo, primero programaremos un caso de respuestas inconsistentes. En este caso, se verificará que no haya casos su edad (c14_1_1) no sea consistente con su nivel educacional (d12_1_1). Para ello, se utilizará la BBDD alterada con errores.
# cargar bbdd
df <- read_sav("BBDD/BASE_USUARIO_alterada.sav")
# crear id (el mismo que el caso anterior)
df <- df %>%
mutate(Id = paste0(id_vivienda, id_hogar, n_linea_h, id_persona, n_linea_p))Como se observa en la tabla de salida, tenemos 6 errores con casos cuya edad es inferior a los 20 años, pero declaran poseer estudios de magíster o doctorado.
##ERRORCON_1: Responde que tiene estudios de magister o doctorado y edad inferior a 21 años
data_errorcon <- df %>% mutate(ERRORCON_1 = case_when(c14_1_1 <= 21 & (d12_1_1 == 14 | d12_1_1 == 15) ~ 1, TRUE ~ 0))
data_errorcon_ce_1 <- data_errorcon %>% filter(ERRORCON_1 == 1)
data_errorcon_ce_1 <- data_errorcon_ce_1 %>% select(Id,ERRORCON_1,c14_1_1,d12_1_1)
knitr::kable(data_errorcon_ce_1, caption = "Tabla: Identificación de observaciones con ERRORCON_1")| Id | ERRORCON_1 | c14_1_1 | d12_1_1 |
|---|---|---|---|
| 331104 | 1 | 17 | 14 |
| 551173 | 1 | 7 | 15 |
| 20211763 | 1 | 17 | 15 |
| 21221813 | 1 | 19 | 14 |
| 293011023 | 1 | 18 | 15 |
| 434411513 | 1 | 16 | 15 |
5.4 Errores de rango
Para el caso de los errores de rango, se hará uso de un loop para delimitar el límite inferior y superior en el que se espera que se encuentren los valores, generando un error cuando el valor observado se encuentra fuera de ese rango. En este caso, se utilizará la BBDD corregida, estableciendo un rango de edad que se mueve entre 0 y 99 años.
5.4.1 a) creación de excel y criterios de rango
Para lograr automatizar el proceso, es necesario generar un excel con las siguientes características
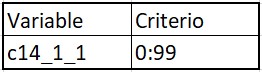
Donde:
Variable: son todas aquellas variables que queremos identificar el correcto rango.Criterio: rango que deben contener las respuestas
5.4.2 b) aplicación del loop
El loop que viene a continuación se encuentra automatizado. Si se han seguido correctamente los pasos anteriores y el excel se encuentra correctamente construido no deberían haber problemas en su ejecución.
En este sentido, lo primero que debemos hacer es cargar nuestro excel con las preguntas listas.
library(readxl)
varsrango <- read_xlsx("BBDD/ERRORCON2_EJ.xlsx")Luego, crearemos vectores específicos con los elementos provenientes de nuestro excel.
# vectores de variables y criterios ---------------------------------------
var<-c(varsrango$Variable)
criterio.rango<-c(varsrango$Criterio)
criterio.rango<- str_replace(criterio.rango, "\\.", ",")El siguiente paso es generar un nuevo objeto donde se almacenen los resultados del loop y que contenga el Id del encuestado, para poder así identificar el caso a caso.
# la seleccion del Id puede cambiar segun BBDD. En este ejemplo el id se
# llamada "Id".
### OJO: si cambian el nombre de "erroresprog" deberán cambiarlo también dentro del loop ###
erroresrango <- df %>% select(Id)Finalmente, ejecutamos el loop:
# LOOP --------------------------------------------------------------------
# Creamos una funcion que servira para traducir en una secuencia de numeros imputs
# como "1 3" o "9". Para ambos casos devolver?a "1 2 3" y "9" respectivamente
secuencia<-function(objeto){
n<-length(objeto)
seq(objeto[[1]],objeto[[n]])
}
#
for (i in 1:length(var)){
ifelse ((str_detect(criterio.rango[i],",")),
rango<- criterio.rango[i] %>% str_split(",") %>%
unlist() %>% as.numeric(),
rango<-criterio.rango[i] %>% str_split(":") %>%
unlist() %>% as.numeric() %>% secuencia
)
coordenada1<-grep(paste("^",var[i],"$",sep=""), names(df))
variable1<-as.numeric(unlist(df[,coordenada1]))
na.check<-(is.na(variable1))*1
rango.check<-(variable1 %in% rango)*1
revision<-paste0(na.check,rango.check)
erroresrango<-cbind(revision,erroresrango)
rm(coordenada1, i, na.check, rango.check, rango, variable1, revision)
}
# Creamos un vector vacio para almacenar los nombres de las variables
nombres.u<-c()
# Ingresamos los nombres de las columnas del data frame de revision, pegando los
# nombres de las variables y salto llegada que correspondan, mas el criterio de salto
for (i in 1:length(var)){
x1<-paste0(var[i], " (",criterio.rango[i],")")
nombres.u<-append(nombres.u,x1)
}
# Reordenar base de datos de revision y añadir etiquetas
erroresrango<-rev(erroresrango)
etiquetas<- append("id", nombres.u)
colnames(erroresrango)<-etiquetas
rm(criterio.rango, etiquetas, i, nombres.u, var, x1, secuencia)
# Recodificacisn sugerida de las observaciones
erroresrango<-erroresrango %>%
dplyr::mutate_at(c(2:ncol(erroresrango)), dplyr::recode,
'00'='Fuera de rango',
'01'='Rango correcto',
'10'='NA')Una vez tengamos los resultados del loop insertos en nuestro objeto erroresrango, podemos generar tablas de frecuencia que nos indiquen la cantidad de errores de rango en las variables.
Para ello utilizaremos la librería sjmisc y su función frq.
library(sjmisc)
# Para generar reportes solo pedimos de la frecuencia de las variables de interes
# frq(errorprog$variable_x)
frq(erroresrango$`c14_1_1 (0:99)`)##
## x <character>
## # total N=34575 valid N=34575 mean=2.00 sd=0.01
##
## Value | N | Raw % | Valid % | Cum. %
## -------------------------------------------------
## Fuera de rango | 1 | 0 | 0 | 0
## Rango correcto | 34574 | 100 | 100 | 100
## <NA> | 0 | 0 | <NA> | <NA>Como vemos, solo tenemos un caso que no cumple con el rango establecido