3 Automatización de tabulaciones de variables (de frecuencia, contingencia y diferencia de medias)
3.1 Tablas de frecuencia/contingencia
Gran parte del trabajo que realiza el analista es manipular y presentar datos cualitativos. Debido a esta frecuencia en el uso de estas técnicas, es mucho más eficiente contar con una herramienta (en este caso un script) que nos permita automatizar el proceso de generación de tablas.
Para lograr generar estas tablas realizaremos los siguientes pasos:
3.1.1 1. Cargar nuestra BBDD
# cargamos nuestra bbdd en formato .sav con la librería haven
library(haven)
# Definir directorio propio (quitar comentario)
# getwd()
# IMPORTAR BBDD
director <- read_sav("BBDD/220244 BDD_director_escalas.sav") # cargar base
summary(director$Pond_Nac) # resumen estadístico del ponderador (si aplica)## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 0.7903 0.7903 0.7903 1.0000 1.3146 1.31463.1.4 4. Creación de secciones (Recomendado)
Cuando necesitamos generar múltiples tablas es mejor separar la base de datos por secciones, pues calcular múltiples tablas de diversas variables puede hacer que el computador se congele.
Para este caso crearemos una sección que contiene veintiún preguntas escalares, la cual guardaremos en formato lista. Si lo deseamos, podemos guardar esa lista en otro objeto particular que haga referencia a ella.
# creamos nuestra seccion con las preguntas que la componen
# para este caso seleccionamos 21 preguntas
seccion_1_prop <- BBDD %>%
select(ConfDir_P1:ConfProc_P21)
# corroboramos que la seccion se componga con las variables requeridas
names(seccion_1_prop)## [1] "ConfDir_P1" "ConfDir_P2" "ConfDir_P3"
## [4] "ConfDir_P4" "ConfDir_P5" "ConfDir_P6"
## [7] "ConfDir_P7" "ConfDir_P8" "ConfDir_P9"
## [10] "ConfDir_P10" "ConfDir_P11" "ConfDir_P12"
## [13] "ConfDir_P13" "ConfDir_P14" "ConfDir_P15"
## [16] "ConfDir_P16" "ConfDir_P17" "ConfDir_P18"
## [19] "ConfDir_P19" "ConfDir_P20" "ConfProc_P21"# creamos una lista que contiene los elementos solicitados ()
list_table_seccion1_banner1 = lapply(seccion_1_prop, function(variable) {
banner_1 %>%
tab_cells(variable) %>%
tab_pct_sig %>%
tab_pivot()
})
# Funcion "lapply": aplica una funcion especifica a cada elemento
# del objeto que se le indique. Para este caso, aplicamos los tabulados
# de frecuencias a toda la seccion_1_prop, arrojando un objeto en formato lista
#Si queremos podemos guardar todas las tablas dentro de un objeto
#ConfDir_P1 <- list_table_seccion1_banner1$ConfDir_P1
### OJO: Esta opcion hace que se pierdan las etiquetas ###
# codigo para obtener un ejemplo de nuestras tablas (para P1 en este caso)
print(list_table_seccion1_banner1$ConfDir_P1)##
## | |
## | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
## | P1_01 A continuación, se enuncian una serie de AFIRMACIONES SOBRE DISTINTOS ESTAMENTOS DE ESTE LICEO, Por favor, marque su nivel de acuerdo o desacuerdo con cada afirmación, considerando que 1 es Muy en desacuerdo y 6 es Muy de acuerdo:Los docentes de es |
## | |
## | |
## | |
## | |
## | |
## | |
## | |
## | |
##
## | #Total |
## ------------------------------ | ------ |
## Muy en desacuerdo | |
## 2 | |
## 3 | 1.6 |
## 4 | 28.4 |
## 5 | 49.5 |
## Muy de acuerdo | 17.9 |
## NR | 2.6 |
## #Número de casos ponderados | 50 |
## #Número de casos no ponderados | 50 |3.2 Tablas de diferencias de medias
Así como buscamos crear tablas de frecuencias/contingencias, también necesitaremos crear tablas que contengan datos cuantitativos. Para este caso haremos tablas con diferencias de medias.
3.2.2 2. Creamos una función que nos permita calcular las diferencias de medias
# esta función se guardará en nuestro enviroment con el nombre de "tab_means_sig"
tab_means_sig = . %>% tab_stat_mean_sd_n( # funcion
labels = c("Mean", # etiquetas que tendran las filas.
"sd", # Siguen el mismo orden que la funcion:
"N")) %>% # mean, sd, n
tab_last_sig_means(bonferroni = TRUE) # TRUE=calcula las diferencias de media3.2.3 3. Creación de secciones (Recomendado)
Cuando necesitamos generar múltiples tablas es mejor separar la base de datos por secciones, pues calcular múltiples tablas de diversas variables puede hacer que el computador se congele.
Para este caso crearemos una sección que contiene veintiún preguntas escalares, la cual guardaremos en formato lista. Si lo deseamos, podemos guardar esa lista en otro objeto particular que haga referencia a ella.
# creamos nuestra seccion con las preguntas que la componen
seccion_1_medias <- BBDD %>%
select(ConfDir_P1:ConfProc_P21)
# corroboramos que la seccion se componga con las variables requeridas
names(seccion_1_medias) ## [1] "ConfDir_P1" "ConfDir_P2" "ConfDir_P3"
## [4] "ConfDir_P4" "ConfDir_P5" "ConfDir_P6"
## [7] "ConfDir_P7" "ConfDir_P8" "ConfDir_P9"
## [10] "ConfDir_P10" "ConfDir_P11" "ConfDir_P12"
## [13] "ConfDir_P13" "ConfDir_P14" "ConfDir_P15"
## [16] "ConfDir_P16" "ConfDir_P17" "ConfDir_P18"
## [19] "ConfDir_P19" "ConfDir_P20" "ConfProc_P21"# creamos una lista que contiene los elementos solicitados ()
list_table_seccion1_banner2 = lapply(seccion_1_medias, function(variable) {
banner_2 %>%
tab_cells(variable) %>%
tab_means_sig() %>%
tab_pivot()
})
# Funcion "lapply": aplica una operacion especifica a cada elemento
# del objeto que se le indique. Para este caso, aplicamos los tabulados
# de media a toda la seccion_1_medias, arrojando un objeto en formato lista
#Si queremos podemos guardar todas las tablas dentro de un objeto
#ConfDir_P1 <- list_table_seccion1_banner2$ConfDir_P1
# Esta opcion hace que se pierdan las etiquetas
# codigo para obtener un ejemplo de nuestras tablas (para P1 en este caso)
print(list_table_seccion1_banner2$ConfDir_P1)##
## | |
## | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
## | P1_01 A continuación, se enuncian una serie de AFIRMACIONES SOBRE DISTINTOS ESTAMENTOS DE ESTE LICEO, Por favor, marque su nivel de acuerdo o desacuerdo con cada afirmación, considerando que 1 es Muy en desacuerdo y 6 es Muy de acuerdo:Los docentes de es |
## | |
## | |
##
## | #Total |
## ---- | ------ |
## Mean | 7.3 |
## sd | 15.2 |
## N | 50.0 |3.3 Exportar tablas a excel
Una vez tengamos los cálculos de nuestras tablas, necesitaremos exportarlas para poder presentarlas de buena manera. Contamos con dos alternativas para esto: 1) exportarlas de manera independiente o 2) exportar ambas tablas (de frecuencias y de diferencias de medias) en un solo archivo excel.
3.3.1 1. Independientes: porcentajes
a) Construir hoja de cálculo en R
# para construir nuestro hoja de calculo de R utilizaremos la libreria "openxlsx"
library(openxlsx)
# crear excel en R
banner_prop = createWorkbook() # generamos documento en blanco.
sh1 = addWorksheet( # generamos una hoja para las diferencias de
banner_prop, "Proporciones") # proporcionesb) Introducir elementos al objeto woorkbook
# para introducir elementos dentro de nuesto objeto excel generado utilizamos la libreria "expss"
library(expss)
xl_write(list_table_seccion1_banner1, # lista con nuestros resultados la seccion 1
banner_prop, # nuestro objeto workbook creado anteriormente
sh1, # hoja especifica para proporciones
col_symbols_to_remove = "#", # eilimanr # de las columnas
row_symbols_to_remove = "#", # eliminar # de las filas
other_col_labels_formats = list("#" = createStyle(textDecoration = "bold")))c) Exportar objeto workbook a excel
# exportar todo lo introducido en banner_prop a excel
### OJO: quitar comentarios para usar ###
# saveWorkbook(banner_prop, # objeto a exportar
# "Diferencias proporcionales.xlsx", # nombre de la hoja
# overwrite = TRUE)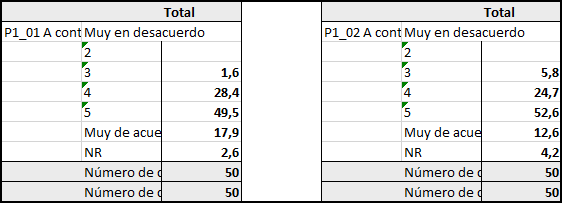
3.3.2 2. Independientes: diferencia de medias
a) Construir hoja de cálculo en R
# para construir nuestro hoja de calculo de R utilizaremos la libreria "openxlsx"
library(openxlsx)
# crear excel en R
banner_medias = createWorkbook() # generamos documento en blanco
sh2 = addWorksheet(banner_medias, # generamos una hoja para
"Diferencias de media") # insertar las mediasb) Introducir elementos al objeto woorkbook
# para introducir elementos dentro de nuesto objeto excel generado utilizamos la libreria "expss"
library(expss)
xl_write(list_table_seccion1_banner2, # lista con nuestros resultados la seccion 1
banner_medias, # nuestro objeto workbook creado anteriormente
sh1, # hoja especifica para docentes
col_symbols_to_remove = "#", # eiliminar # de las columnas
row_symbols_to_remove = "#", # eliminar # de las filas
other_col_labels_formats = list("#" = createStyle(textDecoration = "bold")))c) Exportar objeto workbook a excel
# # exportar todo lo introducido en banner_prop a excel
### OJO: quitar comentarios para usar ###
# saveWorkbook(banner_medias, # objeto a exportar
# "Diferencias de medias.xlsx", # nombre de la hoja
# overwrite = TRUE)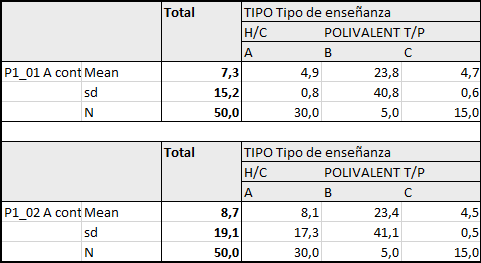
3.3.3 3. En conjunto: porcentaje y dif de medias en un solo archivo
Para exportar un solo archivo excel debemos:
a) Crear banner con sus hojas
# crear banner
banner_full <- createWorkbook() # generamos documento en blanco
sh3 <- addWorksheet(banner_full, # generamos una hoja para insertar las proporciones
"Diferencias proporcionales")
sh4 <- addWorksheet(banner_full,
"Diferencias de medias") # generamos una hoja para insertar las mediasb) Escribir información dentro del objeto workbook
# para introducir elementos dentro de nuesto objeto excel generado
# utilizamos la libreria "expss"
library(expss)
xl_write(list_table_seccion1_banner2, # lista con nuestros resultados la seccion 1
banner_full, # nuestro objeto workbook creado anteriormente
sh4, # hoja especifica para medias
col_symbols_to_remove = "#", # eilimanr # de las columnas
row_symbols_to_remove = "#", # eliminar # de las filas
other_col_labels_formats = list("#" = createStyle(textDecoration = "bold")))
xl_write(list_table_seccion1_banner1, # lista con nuestros resultados la seccion 1
banner_full, # nuestro objeto workbook creado anteriormente
sh3, # hoja especifica para proporciones
col_symbols_to_remove = "#", # eilimanr # de las columnas
row_symbols_to_remove = "#", # eliminar # de las filas
other_col_labels_formats = list("#" = createStyle(textDecoration = "bold")))c) Exportar archivo excel
# exportar todo lo introducido en banner_prop a excel
### OJO: quitar comentarios para usar ###
# saveWorkbook(banner_full, # objeto a exportar
# "Diferencias prop y medias.xlsx", # nombre de la hoja
# overwrite = TRUE)Al exportar nuestro archivo, nos encontraremos dos hojas dentro del mismo archivo excel, una para cada sheet que hayamos agregado en nuestro código de R (en este caso sh3 y sh4 presentes en el código anterior)
